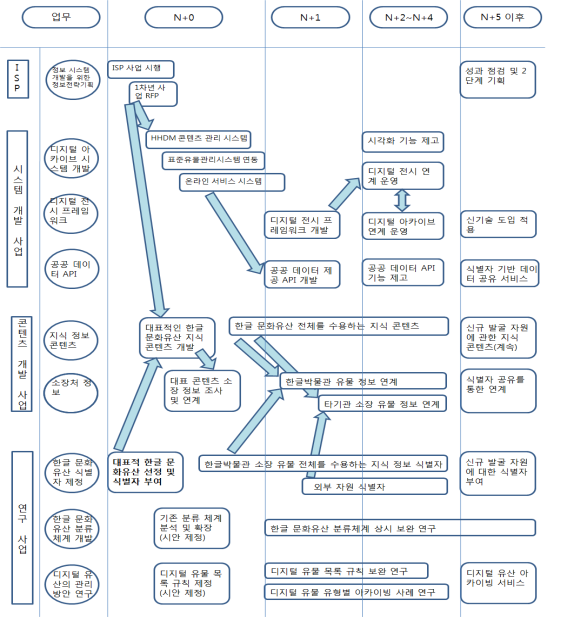
Ⅵ. 국립한글박물관 디지털 아카이브 구현을 위한 로드맵
1. 국립한글박물관 디지털 아카이브 구현을 위한 단계별 추진 과제
제Ⅴ장에서 제시한 데이터 모델에 기초하여 실제로 국립한글박물관에서 운영할 국립한글박물관 디지털 아카이브를 구현하기 위한 후속 업무의 로드맵은 다음과 같이 구상할 수 있다.
[그림 6-1] 국립한글박물관 디지털 아카이브 구현 로드맵
2. 국립한글박물관 정보 시스템 개발을 위한 ISP
ISP(Information Strategy Planning)란 조직의 경영 목표 및 전략을 효과적으로 지원하기 위한 정보 시스템 비전과 전략을 수립하는 과정으로서, 기관 전체 차원의 중장기 정보화 계획을 세우는 것을 말한다. 본 연구(국립한글박물관 디지털 아카이브 구축 기본 구상)도 그 취지와 성격에 있어 이러한 ISP의 한 부분에 해당된다고 할 수 있지만, 이것은 ‘국립한글박물관 정보 시스템’의 일부인 ‘디지털 아카이브’의 비전과 요건을 제시하는 데 목표를 둔 것이므로, 보다 넓은 시각에서 국립한글박물관이라는 조직 전체의 정보 시스템을 설계하는 사업이 시행되어야 하며, 그 안에서 이 ‘디지털 아카이브’의 위상과 기능이 다시 정립되어야 할 것이다.
ISP 사업의 출발점은 조직의 경영 목표, 경영 전략 및 그 조직의 경영 환경에 의한 제약 조건이다. 예를 들어 ‘한글 박물관’이 이상적인 설립 목적을 가지고 출발했다고 해도, 인력과 예산이라는 환경이 제한된 범위의 일만을 수행할 수 있는 상황이라면, 이 조직을 위한 정보 시스템의 설계도 이 점을 반영해야만 한다. 한편으로 인력, 예산, 타 기관과의 실제적인 업무 협력 체계 등 환경적 요인들은 현재의 상황에만 머무는 것이 아니라, 기관의 노력과 국가의 정책 방향에 의해 변화될 수 있는 것이기 때문에, 정보 시스템 역시 실현 가능한 미래 비전을 세우고 여기에 도달하기 위한 단계적인 실천 계획을 수립해야 한다.
‘국립한글박물관 디지털 아카이브 구축 기본 구상’은 국립한글박물관이 유럽의 Europeana와 같은 가상박물관 포털을 운영할 것을 제안하고 있는데, 이러한 구상을 언제까지 어떠한 수준으로 구현할 것인가를 정하는 것도 ISP 사업을 통해서 이루어지게 된다.(예산 및 인력, 정부3.0시책 등 외부 환경 고려)
국립한글박물관에서 운영할 정보 시스템은 본 연구에서 다룬 유물 관리 시스템과 지식 정보 시스템 외에도 전시, 연구, 교육 프로그램의 운영 관리, 시설물의 관리, 인적 자원의 관리 등 국립한글박물관의 경영 전반을 지원하는 역할을 한다. 또한 국립한글박물관은 국가에서 설립 운영하는 정부 기구의 하나이기 때문에 이러한 기능을 지원하는 정보 시스템이 모두 새롭게 개발되는 것이 아니라, 국가 기관들이 이미 공동으로 운영하고 있는 시스템을 활용, 또는 연계 운영할 필요가 있다. 이러한 요인들을 모두 고려한 정보 시스템의 개발 및 중장기 발전 전략이 ISP 사업을 통해 수립되어야 한다.
3. 시스템 개발 사업
ISP 사업을 통해 전사적 정보 시스템의 개발 구상과 단계별 구현 전략이 수립되면, 이에 따라 부문별 시스템 개발 사업이 시행될 수 있다. 국립한글박물관의 경우, 이 시스템 개발 사업은 크게 두 가지로 나누어 볼 수 있다. 하나는 ‘한글 문화유산’에 관한 콘텐츠를 집적하고 서비스하는, 이른바 ‘디지털 아카이브’에 관한 시스템이며, 다른 하나는 ‘한글 박물관’이라는 기관의 운영 업무를 지원하는 시스템이다. 여기서는 전자에 관한 사항만을 다루기로 한다.
1) 국립한글박물관 디지털 아카이브 시스템 개발
디지털 아카이브 시스템 개발 사업은 2 건의 선행 사업(기본 구상 및 ISP) 결과를 토대로 국립한글박물관에서 실제로 운영할 시스템을 구현하는 사업이다.
‘국립한글박물관 디지털 아카이브 구축 기본 구상’이 제안하고 있는 바대로 유럽의 Europeana와 같은 가상 박물관 포털을 운영할 것을 결정하고, ISP 사업을 통해 그 단계적 실천 방안을 마련하였다면, 그 연장선상에서 콘텐츠의 축적 및 연계, 서비스 기능을 수행하는 프로그램(v. 1.0)의 개발이 이루어지게 될 것이다.
이 프로그램은 기본적으로 아래의 5개 클래스의 콘텐츠를 제작하고 서비스하는 기능을 지원한다.
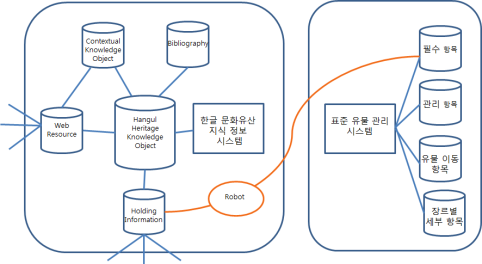
[그림 6-2] 한글 문화유산 지식 정보 시스템
. hhdm:HangeulHeritageKnowledgeObject (한글 문화유산 지식 정보),
. hhdm:HoldingInformation (한글 문화유산 소장 정보),
. hhdm:WebResource (한글 문화유산 관련 월드 와이드 웹 자원),
. hhdm:ContextualKnowledgeObject (한글 문화유산 연계 지식 정보),
. hhdm:Bibliography (참고 문헌 정보)
이 프로그램의 개발은 일정 부분 콘텐츠 제작과 병행하여 이루어져야 하고(적용, 검증을 위해), 또한 양질의 콘텐츠 제작을 위해서는 조사, 연구 사업이 선행되어야 하기 때문에 일시에 전체 시스템의 개발을 모두 완료하기보다는 모듈별 개발의 우선순위를 정해 단계적으로 완성해 나아가는 것도 바람직한 개발 전략일 수 있다. (개발 일정은 ISP 사업을 통해 구체화) 이 경우 ‘한글 문화유산 지식 정보’ 클래스와 ‘한글 문화유산 소장 정보’ 처리 모듈의 개발이 우선되어야 할 것이다.
기본 구상에 의하면, 이 아카이브 시스템은 유물 관리 시스템과 지식 정보 시스템으로 구성되게 되는데, 이중 유물 관리 시스템은 국립중앙박물관에서 개발 보급하는 표준 유물 관리 시스템을 사용하는 것을 제안한다. 이 제안을 따를 경우, 시스템 개발 사업은 ‘지식 정보 시스템’의 개발을 위주로 하되, 유물 관리 시스템과 지식 정보 시스템이 적정하게 연동될 수 있도록 하는 기능을 부가하는 과업이 포함되어야 한다.
① ‘지식 정보 시스템’과 ‘유물 관리 시스템’의 연동
특정 문화유산에 대한 지식 정보를 ‘지식 정보 시스템’에 담고, 그 유물의 소장 정보를 ‘유물 관리 시스템’으로 관리한다는 전제 하에 두 시스템 상의 유관 정보가 실시간으로 연동할 수 있게 하는 기능을 말한다.
완전한 연계를 이루기 위해서는 데이터 수준, DBMS 수준, 응용 프로그램 수준의 3개 층위에서 연계 장치를 마련해야 한다.
- 데이터 수준에서의 연계
지식 정보 시스템 hhdm:HoldingInformation 클래스의 edm:currentLocation 속성으로 표준 유물 관리 시스템 상의 유물번호 값을 기입한다.
표준 유물 관리 시스템의 스키마 확장이 가능하다면 필수항목의 하나로 ‘지식 정보 식별자’ 속성을 부가하고 이곳에 지식 정보 시스템 hhdm:HangeulHeritageKnowledgeObject 클래스의 dc:identifier 속성 값을 기입한다.
이 두 가지는 동일한 관계를 각기 다른 방향에서 기술한 것이므로, 어느 한 쪽 값만 기록되면 나머지는 기계적으로 처리할 수 있다. 기술 방향을 두 가지로 열어 두는 것은 데이터 작성 방법과 절차를 유연하게 할 수 있게 하기 위해서이다.
- DBMS 수준에서의 연계
지식 정보 시스템과 유물 관리 시스템 데이터 사이의 무결성을 체크하고, 잘못된 식별자가 기입되는 것을 방지하는 장치는 DBMS 차원에서 마련될 수 있다.
- 응용 프로그램 차원에서의 연계
데이터를 관리하는 큐레이터의 작업 편의를 위해, 지식 자원 관리 시스템 상에서 유물 소장 정보를 검색, 반입하고, 역으로 유물 관리 시스템 상에서 지식 정보를 검색, 반입할 수 있는 기능을 제공한다.
② 지식 정보 시스템의 관리자 모듈
- 5개 클래스의 콘텐츠를 관리하는 프로그램.
- 데이터의 입력은 1건별로 이루어질 수도 있지만, 보다 많은 경우 위탁연구의 결과물을 일괄 처리로 입력할 것이 예상되므로 XML 반입 기능에 비중을 두어 개발해야 한다.
- XML 데이터 적재를 위한 데이터베이스 스키마는 다음과 같은 3가지 기준을 준수하여 구현한다.
|
√ 단위 노드의 XML 문서는 더 이상 분해하지 않고, 하나의 XML 칼럼(데이터 타입이 XML 문서)에 적재한다. √ 주요 메타데이터 요소는 별도 테이블의 독립 칼럼 데이터로 관리한다. √ XML 본문 칼럼과 메타데이터 칼럼의 데이터는 항상 일치되도록 한다. |
- 지식 정보 관리 시스템의 콘텐츠는 5개 클래스의 정보가 수많은 관계성을 맺고 있으므로 XML 반입, 또는 개별 입력 시에 관계 링크의 정합성을 검증하고, 결과를 리포팅하는 기능이 부가되어야 한다.
③ 지식 정보 시스템의 서비스 모듈
- 지식 정보 시스템의 콘텐츠를 온라인상에서 이용자에게 제공하는 프로그램.
- 5개 클래스의 콘텐츠 상호 연결 고리를 통해 종합적인 지식의 탐색이 이루어질 수 있도록 설계 구현한다.
- 외부 자원 속성(isShownAt, isShownBy)을 통해 타 기관의 유관 자원을 연계 서비스하는 기능을 구현한다.
- 문화유산 지식 객체 및 문맥 정보 클래스의 공간(Place), 시간(TimeSpan) 정보를 기반으로 전자 지도, 전자 연표 서비스 기능을 구현한다.
- 웹 기반의 온라인 서비스 프로그램과 함께 동일한 콘텐츠를 모바일 앱으로 서비스하는 프로그램의 개발을 포함한다.
- 향후, 3차원 공간 형태로 시각화한 플랫폼 상에서 지식 정보 데이터를 탐색, 열람할 수 있게 하는 3D 가상 박물관 운영 프로그램으로 발전할 것을 고려해야 한다.
2) 디지털 전시 프레임워크
- 국립한글박물관의 오프라인 전시 콘텐츠를 시각적인 디지털 콘텐츠로 재현하여 온라인상에서 국민들에게 서비스하는 프로그램.
- 디지털 전시 프레임워크는 다양한 기획 전시 콘텐츠를 용이하게 디지털 콘텐츠로 전환하는 표준화된 틀이다. 오프라인 기획전을 개최할 때마다 이에 대한 디지털 전시 프로그램을 제작하는 것은 적지 않은 비용과 시간을 소요하므로 지속적으로 이루어지지 않게 될 가능성이 많다.
- 그러나 개별 기획전의 전시물품 영상(Still Image, Panoramic View, Object Model 등)과 안내 텍스트만을 끼워 넣으면 즉각적으로 온라인 서비스가 가능한 디지털 전시 프레임워크를 운영할 경우, 한글 박물관의 모든 전시 행사를 용이하게 온라인으로 서비스하고, 이를 지속적으로 축적해 나아감으로써 디지털 아카이브 콘텐츠의 가치를 제고할 수 있다.
3) 공공 데이터 제공 API
- 정부 3.0 시책으로 제정, 발효된 ‘공공 데이터의 제공 및 이용 활성화에 관한 법률(2013.10.31. 시행)’의 취지에 따라 공공 데이터 제공 모듈을 개발한다. 여기서 ‘제공’이라고 하는 것은 “공공 기관이 이용자로 하여금 기계 판독이 가능한 형태(소프트웨어로 데이터의 개별 내용 또는 내부구조를 확인하거나 수정, 변환, 추출 등 가공할 수 있는 상태)의 공공 데이터에 접근할 수 있게 하거나 이를 다양한 방식으로 전달하는 것”을 말하므로, 이를 구현하기 위해서는 외부 이용자가 국립한글박물관의 데이터에 기계적으로 접근하여 데이터를 취득할 수 있도록 하는 API(Application Programming Interface)가 제공되어야 한다.
- 지식 정보 시스템 및 유물 관리 시스템의 데이터가 모두 제공 대상이므로, 외부 이용자가 두 시스템에서 XML 문서 형태의 데이터를 기계적으로 판독·추출할 수 있는 기능을 제공한다.
- 지식 정보 시스템의 XML 문서 형식은 hhdm 데이터 모델 설계에서 확정된 것을 사용하면 될 것이나, 표준 유물 관리 시스템의 XML 데이터 형식은 아직 확정되지 않은 상황이다. 국립중앙박물관측과 이를 협의하여 정하거나, 국립한글박물관에서 먼저 시안을 제정하여 시행함으로써 타 기관에서 이를 좇도록 하는 방법이 있을 수 있다.
4. 콘텐츠 개발 사업
콘텐츠 개발 사업에 관해서는 단기 계획과 중장기 계획의 두 가지 수행 전략이 필요하다. (ISP를 통해 수립) 한글 박물관의 디지털 아카이브 콘텐츠는 궁극적으로 국립한글박물관 내의 전문 연구자들이 조사, 연구, 편찬해야 할 지식 정보이지만(중장기 계획), 시스템 운영 초기부터 이용자들에게 어느 정보 양적 규모를 갖춘 콘텐츠 서비스가 이루어지기 위해서는 외부 조직의 조력에 의한 콘텐츠 생산을 추진할 필요가 있다. (단기 계획)
1) 한글 문화유산 지식 정보 콘텐츠
한글 문화유산 지식 정보 콘텐츠 개발은 지식 정보 시스템의 5개 클래스의 콘텐츠를 조사, 집적, 편찬하는 과제이다.
콘텐츠 편찬 개발의 첫 단계는 대상 항목을 확정하는 것이고, 이것은 국립한글박물관의 연구진이 주체적으로 명확하게 제시하여야 할 부분이다. 단기 과제를 외주 형태로 진행할 경우, 제안요청서 상에 콘텐츠화할 대상 항목의 목록과 식별자1)를 제시하여야 한다.
① 지식 정보 콘텐츠의 범위
한글 문화유산 지식 정보는 궁극적으로 한글 문화유산 전체에 관한 종합적인 지식망을 구성하는 것을 목표로 하지만, 시간과 예산의 제약이 있는 단기 계획에서는 우선순위가 높은 일부를 편찬 대상으로 한정할 수밖에 없다. 이 경우 자료의 중요도뿐 아니라, 편찬의 용이성, 국립한글박물관 소장 유물의 비중 등을 고려할 필요가 있다.
- 우선순위를 정하는 준거로는
. 지정문화재, 등록문화재 등 문화유산으로서의 가치를 인정받은 것.
. 초·중·고등학교의 교과 내용과 연계하여 교육 콘텐츠로 활용할 수 있는 것.
. 한글 문화유산의 다양성을 보이는 예시로 활용 가능한 것. (기록 유산 이외의 유, 무형 문화유산, 디지털 문화유산 등)
. 학술적으로 연구 가치가 높아 저술, 연구논문, 고문헌 해제 등 관련 연구 성과가 산출된 것.
. 국립한글박물관이 실제로 소장하고 있는 유물 가운데 대표 콘텐츠의 역할을 하는 것. (일차로, 오프라인 전시실의 상설 전시 대상인 유물)
등을 고려할 수 있을 것이다.
② 기존 디지털 자원의 재활용(Reuse) 방안
- 한글 문화유산 지식 정보 콘텐츠의 초기 데이터베이스 구축을 위해서는 다음과 같은 기존 자원을 기초 데이터로 활용하는 방안을 강구할 수 있다.
. 국립국어원의 디지털 한글 아카이브 콘텐츠
. 한국어세계화재단의 ‘100대 한글 문화유산 정비 사업’ 보고서
. 한국학중앙연구원의 한국민족문화대백과사전
. 문화재청의 문화재 정보 등
. 국립중앙도서관의 고문헌 종합목록 및 해제
. 서울대학교 규장각의 고문헌 해제
. 한국학중앙연구원 장서각의 고문헌 해제
- 이 경우 기존 자원을 분석·보완하여, 제Ⅴ장에서 제시한 ‘한글 문화유산 지식 정보’(hhdm:HangeulHeritageKnowledgeObject) 모델의 형식으로 편찬하는 것은 새로운 저작으로서 의미를 갖지만, 그러한 노력을 부가하기 어려운 경우에는 외부 자원 연계 방식으로 재활용(Reuse)하는 방안도 강구할 수 있다. HangeulHeritageKnowledgeObject의 edm:isShownAt 및 edm:provider 속성은 그러한 목적으로 사용하도록 만든 장치이다.
- 국립국어원의 디지털 한글 아카이브 콘텐츠의 경우, 이 시스템의 운영권과 데이터를 국립한글박물관에서 인계받는다면, 이를 hhdm 형식으로 재구성하고 보완함으로써 ‘한글 문화유산 지식 정보’의 Prime Model로 삼을 수 있을 것이며, 이를 단기 계획의 우선 과제로 추진할 수 있을 것이다.2)
③ 문맥 정보
- 지식 정보 콘텐츠는 문화유산에 대한 정보뿐 아니라 이른바 ‘문맥 정보’(Contextual Information)3)에 대한 서비스를 포함해야 한다. 이는 문화유산을 설명하는 텍스트에 등장하는 인물(Agent, 기관·단체 포함), 장소(Place), 시대(TimeSpan), 용어(Concept)를 텍스트 상에서 드러나게 하고 그 의미를 적정하게 설명해 주는 ‘문맥 정보 콘텐츠’로 가는 통로를 마련해 주는 것이다.
- 지식 정보 콘텐츠 개발을 외주 사업 형태로 진행하는 경우, 첫 단계에서는 문맥 정보 콘텐츠를 새로 편찬하기보다는 월드 와이드 웹상에서 접근 가능한 외부 자원을 발굴하여 그 연결 고리를 마련하는 방식으로 수행하는 것도 고려할 수 있다. 한글 문화유산을 깊이 있게 이해하는 데 필요한 문맥 정보의 상당 부분은 이미 여러 기관에서 편찬하여 서비스하고 있는 사전류의 디지털 콘텐츠 상에서 발굴할 수 있다4). 서비스 초기 단계에서는 이를 참조 데이터로 재활용(Reuse)하고, 향후 2단계 사업에서 이러한 자원을 집적하고 가공하여 제Ⅴ장에서 제시한 형식으로 구조화한다.
2) 타 기관 소장 정보 연계 서비스 콘텐츠
한글 문화유산 지식 정보 콘텐츠 개발 사업은 국립한글박물관 이외의 타 기관에서 소장하고 있는 ‘한글 문화유산’의 소재지 정보(소장 정보)를 조사하여 그 소재에 관한 데이터를 지식 정보 콘텐츠에 포함시키는 과업을 포함한다. (웹상에서의 Link를 위한 URL 및 최소한의 메타데이터)
- 단기 계획에서는 초기 데이터베이스 등재 지식 정보 데이터 중 국립한글박물관 소장품 이외의 것을 대상으로 삼아 그 유물의 소재지를 조사하고, 타 기관에 디지털화된 소장 정보가 있는 경우 Linked Data를 추출하는 일을 수행한다.
- 중장기 계획에서는 지속적인 조사 연구 업무의 일환으로 국립한글박물관에서 식별자를 부여하는 모든 한글 문화유산의 소재지 정보를 확보해 나아간다.
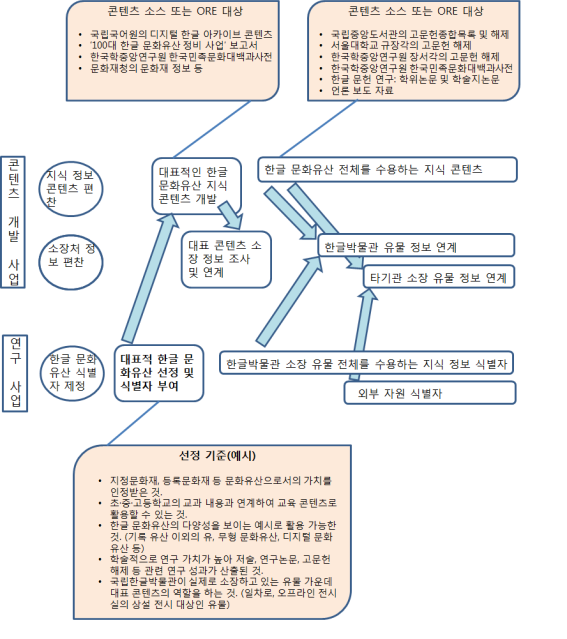
[그림 6-3] 콘텐츠 제작 및 관련 연구 프로세스
5. 연구 사업
한글 문화유산 지식 정보 시스템의 프로그램 개발과 콘텐츠 제작은 범국가적인 한글 문화유산 지식망을 구현하고자 하는 국립한글박물관의 비전과 의지를 기반으로, 합리적인 실천 목표와 구체적인 실천 전략을 강구하면서 추진되어야 한다. 이를 위해서는 국립한글박물관이 주체적으로 사업의 합리성과 효율성을 제고하는 연구 사업을 수행하고, 거기에서 얻어진 성과를 토대로 프로그램 개발 및 콘텐츠 제작 방향을 제시하여야 한다.
1) 한글 문화유산 식별자 제정
장기적으로 볼 때, 한글 문화유산 지식망을 형성하는 중심 노드는 월드 와이드 웹상에서 한글 문화유산 하나하나를 명시적으로 식별할 수 있는 ‘이름’이다. 국민들에게 지식 정보로 제공할 필요가 있는 한글 문화유산의 망라적인 목록을 만들어 내고, 그 하나하나에 대해 인터넷 상에서 식별할 수 있는 이름을 부여하는 작업이 한글 박물관의 디지털 아카이브 운영 팀의 중요한 업무로 부여되어야 한다.
이 업무는 한글 박물관 디지털 아카이브 구축의 초기 단계에서부터 이루어져야 하기 때문에 프로그램 개발이나 콘텐츠 제작 사업을 발주하기에 앞서 정보기술전문가 및 한글 문화재 전문가들의 자문을 받아 초기 데이터베이스에 수록될 한글 문화재의 목록과 식별자 명명 규칙을 확정해야 한다.
2) 한글 문화유산 분류 체계 개발 연구
본 연구에서는 LIDO, Europeana 등 문화유산 데이터의 재이용 및 교환에 관한 선진 사례를 분석하여 한글 문화유산의 다양한 속성을 적정하게 기술하는 형식을 제안하였다. 이 형식에 따라 기입해야 할 데이터 값의 내용은, 그 중에서도 문화유산의 성격 및 유형에 대한 분류는 이 분야의 전문 연구자들에 의해서 별도로 강구되어야 할 과제이다.
본 연구에서 제안하는 한글 문화유산 지식 정보 데이터 모델에서는 대상물의 유형 및 성격을 기술하는 속성으로 dc:type, dc:subject, dc:format, dc:format, dcterms:medium 등을 기술할 수 있게 하였다. 이러한 속성 항목에 어떠한 데이터 값을 기술할 것인가는 한글 문헌 등 한글 문화유산에 관한 전문적인 조예가 있는 연구자들이 원칙과 기준을 정해야 한다.
우리나라에서 박물관 소장 문화유산의 분류 체계와 그에 따른 세부 속성에 대한 연구는 국립중앙박물관에서 지속적으로 수행하여 왔으며, 그곳에서 마련된 표준 유물 관리 시스템의 장르별 항목에 반영되었다.5)
표준 유물 관리 시스템의 장르별 항목은 고미술분야를 중심으로 설정된 것이기 때문에 ‘한글 문화유산’에 해당하는 유물과 특성을 적정하게 반영하고 있다고 보기 어렵다. 그렇지만, 고도서, 비(碑) 등의 유물을 기술하기 위해 마련된 여러 가지 분류 시스템은 한글 문화유산에도 적용할 수 있는 부분이 있을 것이므로, 그와 같은 기존 연구 성과를 심도 있게 점검하여 가용한 부분을 찾아내는 노력이 필요하다.
※ 표준 유물 관리 시스템의 고도서 및 비(碑) 관련 항목에서 사용하는 분류 체계
[고도서]
. 편저년의 성격 분류
. 판원(版原) 성격 분류
. 판종 성격 분류
. 도판 유형 분류
. 형태 유형 분류
. 내용 분류
. 서체 유형 분류
. 인장 성격 분류
[비(碑)]
. 내용 분류
. 형식 분류
한글 문화유산을 대상으로 한 내용 분류의 사례는 현재 국립국어원에서 운영하고 있는 디지털 한글 박물관의 ‘한글 문헌 내용 분류 카테고리’에서 볼 수 있다. 매우 소략한 분류 체계이기는 하나, 이 분야의 전문 연구자들 중에는 이보다 상세한 내용 분류 연구를 한 이들이 있을 것이므로, 이들의 전문적인 연구 성과를 반영한 내용 분류 틀을 마련할 필요가 있다.
※ 디지털 국립한글박물관의 한글 문헌 분류 체계 (주제별 9 분류)
1. 문학류 : 1-1. 시가 / 1-2. 산문
2. 종교류 : 2-1. 불교 / 2-2. 유교 / 2-3. 도교 / 2-4. 기독교
3. 교화류
4. 기술류 : 4-1. 의약 / 4-2. 농사 / 4-3. 병학 / 4-4. 기타
5. 외국어 학습류
6. 사전류 : 6-1. 운서 및 옥편 / 6-2. 현대 사전
7. 일상생활류 : 7-1. 한글 편지 / 7-2. 각종 문서
8. 학습 교재류 : 8-1. 교과서 / 8-2. 기타 학습서
9. 연구 및 규범류 : 9-1. 연구서 / 9-2. 어문 규범
3) 디지털 유산의 관리 및 보존, 전시 방안 연구
지금까지 박물관이나 기록관에서 ‘디지털’은 주로 아카이빙 자료의 디지털 복제나 메타데이터의 디지털 정보화를 뜻하는 의미로 쓰였으나, 최근 들어 디지털 형태의 사물 그 자체가 ‘문화유산’으로 취급되는 현상을 보게 된다. 2013년 6월 우리나라의 대표적인 문서 편집 소프트웨어 ‘ᄒᆞᆫ글’의 최초 버전(1989년 4월 출시)이 등록 문화재로 지정되었는데, 명목상 물리적인 형태를 갖춘 소프트웨어 패키지를 문화재로 지정한 것이지만, 실제적으로는 당대의 기술과 문화의 한 단면을 보여 주는 디지털 소프트웨어가 문화유산으로 인정된 사례라고 볼 수 있다. Europeana에서도 태생적으로 디지털(born digital)인 문화유산 정보를 기술하는 장치를 마련하고 있는데, 이는 디지털 문화유산에 대한 이해가 그만큼 높아졌음을 보여 주는 것이다.
디지털 문화유산의 관리 및 보존, 전시는 이제 여러 박물관이 기록관에 관심을 가져야 할 주제가 되었지만, 우리나라에서는 국립한글박물관이 이 임무에 관한 선도적인 역할을 할 것으로 기대된다. 현대 사회에서 ‘한글’이라고 하는 문자 언어는 디지털과 밀접한 관계를 맺고 있기 때문이다.
① 디지털 문화유산의 범위
UNESCO가 제시한 ‘디지털 유산의 보존을 위한 가이드라인’6)에 의하면 디지털 유산은 다음과 같은 4 가지 층위에서 이해되어야 하고, 그 각각의 층위에 맞는 보존 방안이 강구되어야 한다.
- ‘물리적 오브젝트’(Physical Object): 무형의 소프트웨어나 디지털 데이터라고 하더라도 그것은 어딘가에 컴퓨터 디스크나 서버와 같이 물리적인 오브젝트에 수록된 형태로 있게 된다. 이처럼 디지털 신호를 담고 있는 물리적 오브젝트를 디지털 문화유산으로 보는 것이 첫 번째 시각이다.
- ‘논리적 오브젝트’(Logical Object): 물리적 오브젝트로부터 컴퓨터가 읽어들일 수 있는 디지털 코드를 지칭한다. 소프트웨어나 디지털 데이터를 뜻한다고 할 수 있다.
- ‘개념적 오브젝트’(Conceptual Object): 물리적이거나 논리적인 차원을 벗어나, 인간(사용자)이 디지털 오브젝트에 접근할 때 발생하는 개념적이고 의미적인 것들을 지칭한다. 기술적 환경 변화로 물리적 하드웨어나 논리적 코드가 바뀌더라도 그 개념과 의미를 유지하는 ‘기능’ 또는 ‘디자인’이 개념적 오브젝트에 속한다고 할 수 있다.
- ‘일련의 필수 요소(Bundles of Essential Elements)’: 디지털 유산은 그것에 대한 접근이나 사용이 가능해야지만 ‘보존’이라고 할 수 있다. 그것을 문화유산으로 선택한 필수적인 이유가 드러나도록 하는 데 필요한 요소들이 디지털 문화유산의 범위에 들어가야 한다.
디지털 문화유산에 대한 관심을 촉구하고 그것의 보존 방안을 강구하고 있는 UNESCO의 선도적 활동과 업적은 디지털 문화유산의 관리 방안을 찾는 모든 실천적 연구 개발 노력의 출발점이 될 수 있다. ‘한글 문화유산’이라는 영역에서는 이 4 가지의 층위가 무엇에 해당하는지 판단하고 그에 적합한 관리 방안을 강구해 나아갈 필요가 있다.
향후 국립한글박물관에서 문화유산으로 취급하여 그것의 수집, 보전, 전시 방안을 마련해야 할 대상은 한글 교육을 위한 소프트웨어, 디지털 폰트, 전자사전의 데이터, 한글과 관련된 그래픽 디자인, 영상, 음원 등 매우 다양할 것이다. 새로운 유형의 디지털 유물이 입수, 등록될 때마다 그것에 적합한 전시 서비스 및 아카이빙 서비스 방법을 찾는 케이스 스터디(case study)를 수년간 시행하고(2014~2017, 중기 계획으로 시행) 그 성과를 종합하여 디지털 문화유산 관리의 원칙과 기준, 아카이빙 서비스 방법을 정립할 것을 제안한다.
② 물리적 오브젝트의 목록 관리
디지털 문화유산의 관리 방안은 중장기적인 연구 사업을 통해 마련해 가야 하겠지만, 물리적 오브젝트 형태의 디지털 유산(ᄒᆞᆫ글 1.0 패키지와 같은 것) 몇 가지를 유물로 등록하고 관리하는 일은 시급히 그 방안을 찾아야 하는 과제라고 할 수 있다.
이를 위해서는 국립한글박물관에서 운영할 유물 관리 시스템 안에 ‘디지털 유물’에 관한 사항을 기록할 수 있는 장치를 마련해야 하는데, 도서관에서 기계가독형 목록(MARC)의 생산에 적용하고 있는 Digital Resource의 Cataloging Rule을 도입 적용하는 방안을 우선적으로 고려할 수 있을 것이다.
※ 기계가독형 도서목록(MARC)상의 디지털 자원 기술 요소7)
|
Leader/06 Type of Record: m - Computer file 008/26 File Type: a – numeric data b – computer program f – font g – game i – interactive multimedia j – online system or service |
1) URI, 제Ⅴ장에서 설명한 ‘한글 문화유산 지식 객체 식별자;(Knowledge Object Identifiers for Hangul Heritage)
2) 디지털 한글 아카이브 콘텐츠의 활용 방안은 제Ⅷ장에서 상론.
3) Information we know that is relevant to an understanding of the text: •The identity of things named in the text: people, places, books, etc. •Information about things named in the text: birth dates, geographical locations, date published, etc. •Interpretive information: themes, keywords •Normalization of measurements, dates, etc. (What is contextual information?, Brown University, http://www.wwp.brown.edu/outreach/seminars/_current/presentations/metadata/metadata_03.xhtml)
4) 한국학중앙연구원의 민족문화대백과사전, 역대인물종합정보 등
5) 표준 유물 관리 시스템의 장르별 항목은 도자기, 일반회화, 불상, 불화, 고도서, 복식, 가구, 탑, 승탑, 비, 석등, 화살촉 등 12개 부문이며, 부분별 세부 속성 항목은 도자기 9, 일반 회화 12, 불상 8, 불화 7, 고도서 24, 탑 7, 승탑 5, 비 3, 석등 3 등 78개이다.
6) UNESCO, 2003. 3. Guidelines for the Preservation of Digital Heritage
7) OCLC, Cataloging Electronic Resources: OCLC-MARC Coding Guidelines, http://www.oclc.org/support/services/worldcat/documentation/cataloging/electronicresources.en.html?urlm=19365 )